Unsere vernetzte Welt verstehen

Schuldzuweisungen in einer Welt nach Trump
Waren sogenannte fake news oder Big Data verantwortlich für den Wahlerfolg Donald Trumps? Verfolgte man die massenmediale Berichterstattung über die letzten Wochen, so konnte man diesen Eindruck gewinnen. Doch der täuscht. Vielmehr zeugt die verzweifelte Suche nach einem Schuldigen von einem gesellschaftlichen Misstrauen gegenüber dem Internet, dem alles zugetraut und auf das alle Ängste projiziert werden können. Eine akkurate Analyse bleibt aus, während ein Medienwirkungsverständnis vorherrscht, in dem immer nur die anderen blind den Medien glauben.
Donald Trump’s victory came as a surprise and/or shock to most pollsters, journalists, scientists, and citizens all over the world. And ever since Trump became the president-elect one question seems to be on many people’s minds: „who is to blame?“ The answers to this question ranges from the electoral system to international influence but one particular scapegoat is more prominent than others: the internet.
Indeed, not short after Trump’s victory Buzzfeed had identified the first villain: fake news. In their analysis they suggested „that top fake election news stories generated more total engagement on Facebook than top election stories“ from other serious outlets. The threat of fake news was born. And other mass media outlets followed. We have probably all heard or read about fake news in the last month one way or the other. About the one Macedonian village where youths wrote fake news to earn money or the American fake news writer who suggested that he was responsible for Trump’s victory and who claimed that he mostly created fake stories for Republicans since these were more gullible than Democrats. And the narrative not only resonated with journalists but also citizens who suddenly started googling for fake news (see Fig. 1) and found dozens of news articles that were painting a dark picture: not only are we living in a post-truth world, but our society is also fragmented into numerous echo chambers in which fake news is shared freely, thus eroding our society’s basis. And according to a computer scientist it’s not clear whether fake news won Trump the election but „there are reasons to believe it is entirely possible.“
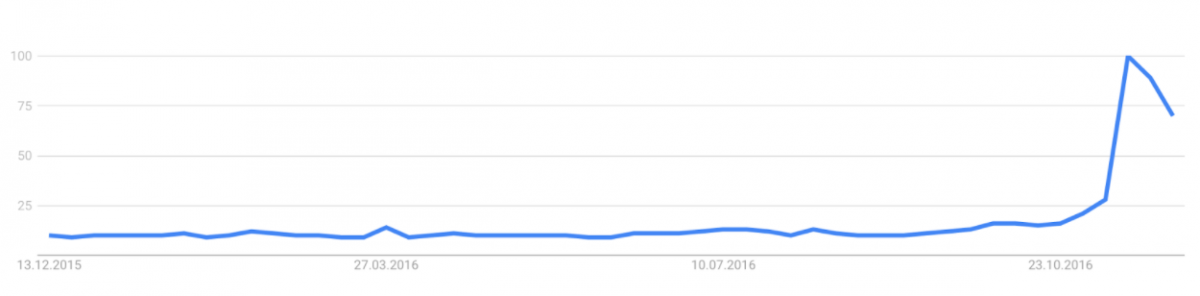
But is fake news really that problematic? Well, the short answer is: we don’t know. However, it’s also nothing particularly new. Not taking into account that fake news are probably as old as the mass media (think of the party newspapers in 1920s Germany, for example), it is also nothing new online. In fact, scholars have been researching something similar for quite some time now: rumors. Several studies have been conducted that looked at the spread of rumors on Twitter and compared them to real news stories. They found that there are distinct differences in the way rumors spread: not only are rumors more similar to epidemics than news stories in the way they spread, real news stories are also picked up by more users than rumors, and, related, rumors usually stay within rather closed communities and do not travel far. As rumors seem to have a very distinct online fingerprint a study was able to identify rumors automatically on Twitter with a precision of 70 to 80%. And another study which makes use of automated text analysis even promises up to 97% thus also showing that rumors aren’t shared with the same language as factual stories are.
So if we already have a good idea of how to identify rumors or fake news based on the way it is shared and how it spreads in social networks, the question, then, is not how we identify it but rather who is influenced by it. And that is usually the point where many people abandon all reason and project their biggest fears on the other, because even though they are not affected by the news (how could they?!), the others surely will be. Meaning that you and I, obviously, are not affected by fake news but what about the people who are not as smart/educated/critical/literate/etc.? This is what we communication scholars call third-person effect. Indeed, studies have shown that the third-person effect is diminished when the impact may be desirable for society but amplified when the impact is seen as negative. So, generally speaking, we assume that the media has only a bad influence on people but not a good one. And although a study was able to show that political rumors can have a consequence on how people vote when they believe the rumors about a candidate, the question is if fake news are able to convince people in the first place. Indeed, it is more likely that fake news are rather circulated in communities that are already convinced about a certain issue anyway and thus only pass on news that is in line with that conviction. The problem, then, is not fake news and not even the internet, but how people choose news based on their convictions. And that, indeed, is not fake but rather old news.
Then the dust somewhat settled and the media’s and public’s attention slowed down. And the second culprit was found: Facebook. Cambridge Analytica. Or big data. Or psychometrics. Or marketing. Or all of the above. In an article that was widely shared in German-language online publics (see for a proxy Fig. 2; English take on the issue) two journalists described the psychological science behind clustering people into specific categories based on their likes on Facebook and other data, that, then, can be marketed to specifically. And since Cambridge Analytica was working for Donald Trump, had worked on Brexit, and was making practical use of this psychological research and not only targeted potential Trump voters but also tried to depress potential Clinton voters from casting their vote, the public outrage was high.
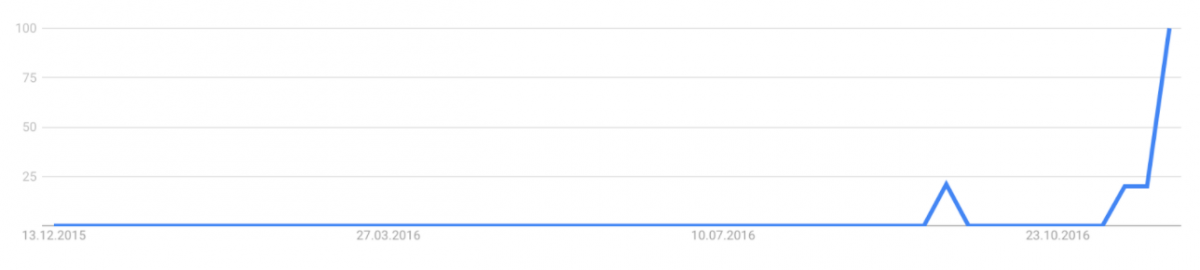
Fig. 2: Google Trend results for ‘cambridge analytica’ in Germany
And even though shortly after the article broke, German news outlets surpassed each other in downplaying Cambridge Analytica’s role and in being skeptical about its potential impact (1, 2, 3)[1], the story is in line with a broader distrust of the internet and big data that is both being displayed with fake news as well as with big data. This distrust, however, is misplaced. But not because there are no reasons for distrusting Facebook, fake news, or marketing agencies. There certainly are more than enough reasons for why they shouldn’t be trusted. Indeed, both topics raise important questions ranging from how we can differentiate fake news from lies, rumors or conspiracies, if there are differences in how they spread online in social networks, or whether scientists should be more careful in the way they communicate their findings, or whether marketing companies should be held to a higher ethical standard. But these questions are not being discussed. Instead, it’s Facebook, it’s big data, and it’s the internet.
This distrust, then, is misplaced because it distracts from the real problem. That we project our fear and shock of an election gone wrong onto the internet in hope of finding a culprit that could explain why we were wrong all along and why we, as a society, are not responsible. We ask the right questions, but for the wrong reasons. Or do you think we would have these conversations if Hillary Clinton won?
[1] Note, however, that the actual science is rarely discussed in the media (e.g. 1, 2, 3). Indeed, it is not without irony that the story the German mass media is more critical about is most likely the one with a more substantiated concern.
Photo: CC BY-SA 2.0
Dieser Beitrag spiegelt die Meinung der Autor*innen und weder notwendigerweise noch ausschließlich die Meinung des Institutes wider. Für mehr Informationen zu den Inhalten dieser Beiträge und den assoziierten Forschungsprojekten kontaktieren Sie bitte info@hiig.de

Jonas Kaiser

Jetzt anmelden und die neuesten Blogartikel einmal im Monat per Newsletter erhalten.

Plattform Governance

Kann KI die Demokratie stärken? Ein Datensatz zu KI-Projekten, die demokratische Prozesse unterstützen möchten
Ein Datensatz mit über 98 KI-Projekte mit demokratischem Anspruch dient als Grundlage für mehr Forschung zu KI und Demokratie.

Zwischen Zensurvorwurf und Plattformmacht: Was der Digital Services Act wirklich regelt
Der DSA wird zunehmend als "Zensurgesetz" angegriffen. Dieser Beitrag argumentiert: Im Kern soll das Gesetz die Meinungsfreiheit im digitalen Raum schützen.

Demokratie zum Ankreuzen: Unsere Wahlkabine bei der Langen Nacht der Wissenschaften
Wir haben Berliner*innen eingeladen, ihre Haltungen zu Demokratie in Deutschland zu teilen. Die Ergebnisse erscheinen hier in Kürze.