Unsere vernetzte Welt verstehen

Inside Hugging Face
Um die Dynamiken der Open-Source Machine Learning Forschung zu verstehen, ist eine Plattform von zentraler Bedeutung: Hugging Face. Wer an die neuesten Machine Learning Modelle kommen will, wird auf Hugging Face fündig. In diesem Beitrag beleuchte ich, wie sich die Modelle in den letzten Jahren verändert haben und welche Organisationen auf der Plattform aktiv sind.
Hugging Face statt OpenAI
Während sich ein Großteil der jüngsten Berichterstattung über KI auf OpenAI, dem Unternehmen hinter ChatGPT, konzentriert, wird einem anderen Unternehmen, das für den Alltag von Machine Learning (ML) Entwickler*innen viel relevanter ist, weitaus weniger Aufmerksamkeit geschenkt: Hugging Face. Hugging Face ist eine Plattform, die ML-Modelle, einschließlich großer Sprachmodelle (LLMs), hostet. Auf dieser Plattform kann buchstäblich jede*r Modelle hoch- und herunterladen. Sie ist eine der wichtigsten Triebkräfte für die Demokratisierung der ML-Forschung. Wenn wir verstehen, welche Akteur*innen und Modelle sich auf Hugging Face befinden, können wir viel über die aktuelle Open-Source-Forschung im Bereich ML erfahren.
Das Unternehmen hinter dem Emoji
Hugging Face ist ein junges Unternehmen, das 2017 in New York City gegründet wurde. Sein ursprüngliches Geschäftsmodell war die Bereitstellung eines Chatbots. Mittlerweile ist es jedoch vor allem als Plattform bekannt, das zunächst nur Sprachmodelle hostete, aber in den letzten Monaten wurden Bild, Sprache und andere Modalitäten hinzugefügt. Neben dem kostenlosen Hosting werden auch einige kostenpflichtige Dienste angeboten, wie z. B. ein Hub zur Bereitstellung von Modellen. Hugging Face wird derzeit mit zwei Milliarden Dollar bewertet und ist kürzlich eine Partnerschaft mit Amazon Web Services eingegangen.
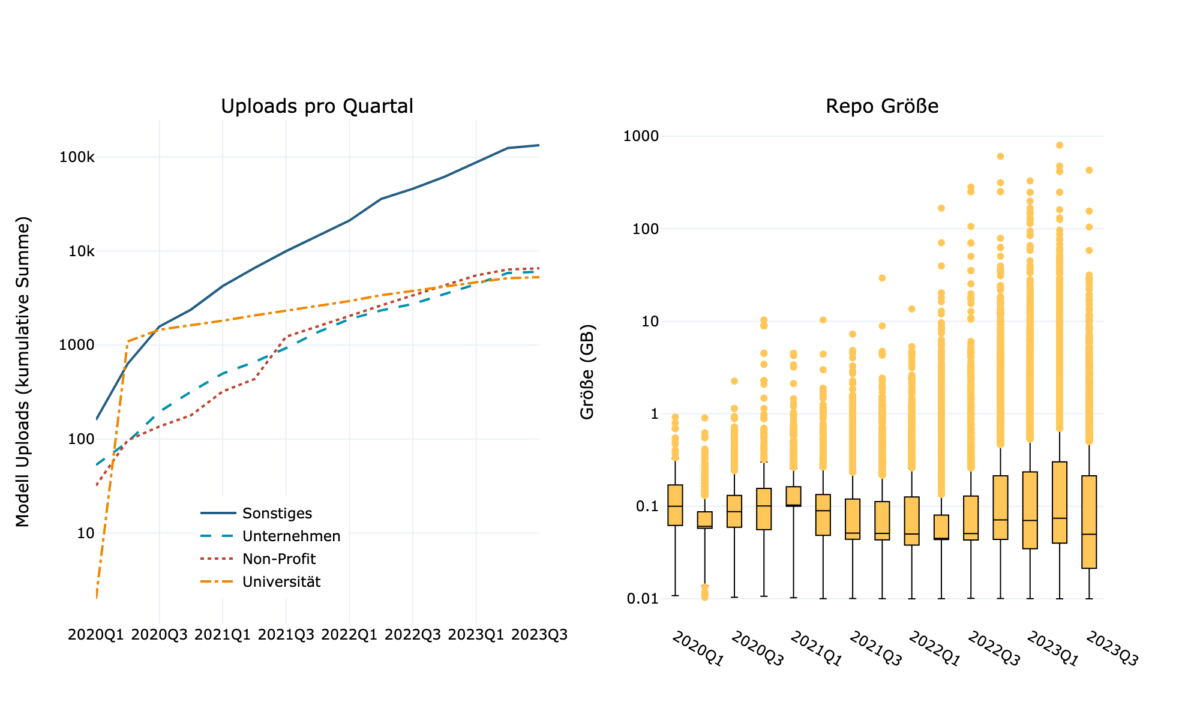
Modelle werden größer
Wie in Abb. 1 zu sehen ist, nehmen die Beiträge zu Hugging Face ständig zu und die Größe der Repositorien wächst mit der Zeit. Das bedeutet, dass immer größere Modelle hochgeladen werden, was die jüngsten Entwicklungen in der KI-Forschung widerspiegelt. Viele der Modelle werden von Unternehmen, Universitäten oder Non-Profit-Organisationen zur Verfügung gestellt, die meisten stammen jedoch von Einrichtungen, die keine Angaben über sich machen („Sonstiges“). Eine manuelle Überprüfung zeigt, dass es sich dabei meist um Einzelpersonen handelt, die ein oder mehrere Modelle hochgeladen haben, aber auch um Organisationen, die einfach keine Angaben machen.
Welche Organisationstypen sind auf Hugging Face aktiv?
Wer lädt die meisten Modelle hoch und wessen Modelle sind am meisten gefragt? Die größte Gruppe in Bezug auf die hochgeladenen Modelle ist „Sonstige“ (Abb. 2). Die übrigen Gruppen, mit Ausnahme von „Classroom“, liegen ziemlich dicht beieinander. Das bedeutet, dass Universitäten, gemeinnützige Organisationen und Unternehmen etwa einen gleich großen Beitrag auf Hugging Face leisten.
Der jüngste Aufschwung in der ML-Forschung wird hauptsächlich von Big Tech und Eliteuniversitäten vorangetrieben, da das Training großer Modelle extrem ressourcenintensiv ist, sowohl was den Rechenaufwand als auch was die Kosten angeht. Dementsprechend würde man erwarten, dass die meisten großen Modelle von Unternehmen oder Universitäten stammen und ihre Modelle auch am häufigsten heruntergeladen werden. Dies ist jedoch nur teilweise der Fall. Modelle von Unternehmen und Universitäten sind tatsächlich am meisten gefragt. Während die von Unternehmen hochgeladenen Modelle jedoch auch relativ groß sind, sind es die Modelle von Universitäten nicht. Die größten Modelle werden von Non-Profit-Organisationen hochgeladen, was jedoch hauptsächlich auf einige Modelle von LAION und Big Science zurückzuführen ist, weil jedes ihrer Modelle mehr als hundert Gigabyte groß ist.

Upload und Download sind nicht gleich
Was sind die einzelnen Organisationen, die am meisten zu Hugging Face beitragen? Bei den Universitäten ist die University of Helsinki, die Übersetzungsmodelle für verschiedene Sprachkombinationen bereitstellt, mit Abstand führend (Abb. 3). Bei den Downloads ist jedoch das japanische Nara Institute of Science and Technology (NAIST) auf Platz 1. Dies ist vor allem auf MedNER zurückzuführen, ihr Modell zur Erkennung von benannten Entitäten in medizinischen Dokumenten, das ebenfalls unter den Top 10 der am häufigsten heruntergeladenen Modelle auf Hugging Face zu finden ist. Deutsche Universitäten gehören zu den Organisationen mit der höchsten Modellanzahl, aber auch mit den meisten Downloads.
Den Non-Profit-Repositorien mit den meisten Modellen sollte man nicht allzu viel Vertrauen schenken, da drei von ihnen von einem einzigen Doktoranden unterhalten werden. Die Organisationen in dieser Kategorie mit der höchsten Downloadrate sind jedoch bekannte gemeinnützige Organisationen wie LAION und BigCode, die viel zur Open-Source-Gemeinschaft beitragen.
Wenig überraschend führen große Tech-Unternehmen die Kategorie „Industrie“ bei den Uploads an. Allerdings sind es weder Google noch Facebook, die die höchste Download-Rate aufweisen, sondern Runway mit Stable Diffusion.
Die Top 10 der am häufigsten heruntergeladenen Modelle wird von Wave2Vec, einem Spracherkennungsmodell, angeführt. Es ist überraschend, dass, obwohl Hugging Face lange Zeit als Plattform für unimodale Sprachmodelle bekannt war, viele der am häufigsten heruntergeladenen Modelle bimodal für Text und entweder Bild oder Sprache sind.

Open-Source LLMs sind im Aufstieg
Spätestens seit dem Erscheinen von ChatGPT haben LLMs ihren Weg in die öffentliche Aufmerksamkeit gefunden. Wie aus einem kürzlich durchgesickerten Memo eines Google-Entwicklers hervorgeht, wird Open-Source jedoch zu einem ernsthaften Konkurrenten für LLMs. Hugging Face hat ein Leaderboard für offene LLMs gestartet und einige von ihnen erreichen eine Leistung, die der von ChatGPT nahekommt.
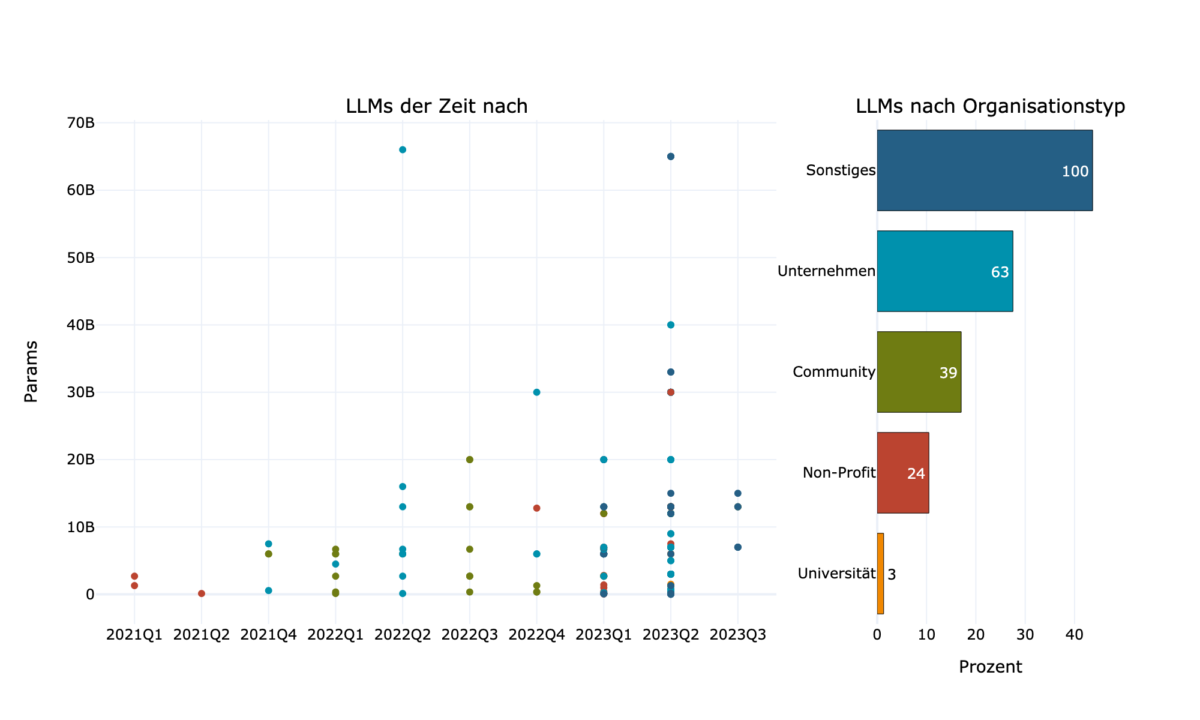
Die Modellgröße, gemessen in Parametern, ist in den letzten Jahren drastisch gestiegen (Abb. 4). Während im Jahr 2021 nur wenige Modelle 3 Milliarden Parameter erreichten, gibt es derzeit viel mehr und größere offene Modelle, die fast 70 Milliarden Parameter erreichen.
Der Organisationstyp, der die meisten LLMs hochlädt, ist „Sonstige“. Dies ist jedoch hauptsächlich auf einige wenige Akteur*innen zurückzuführen, die manchmal sogar mehr als 15 Modelle hochgeladen haben. Die Gruppe, die die zweitmeisten LLMs hochlädt, sind Unternehmen, mit durchschnittlich 10 Milliarden Parametern. Universitäten hingegen laden nicht nur die wenigsten LLMs hoch, sondern im Durchschnitt auch die kleinsten.
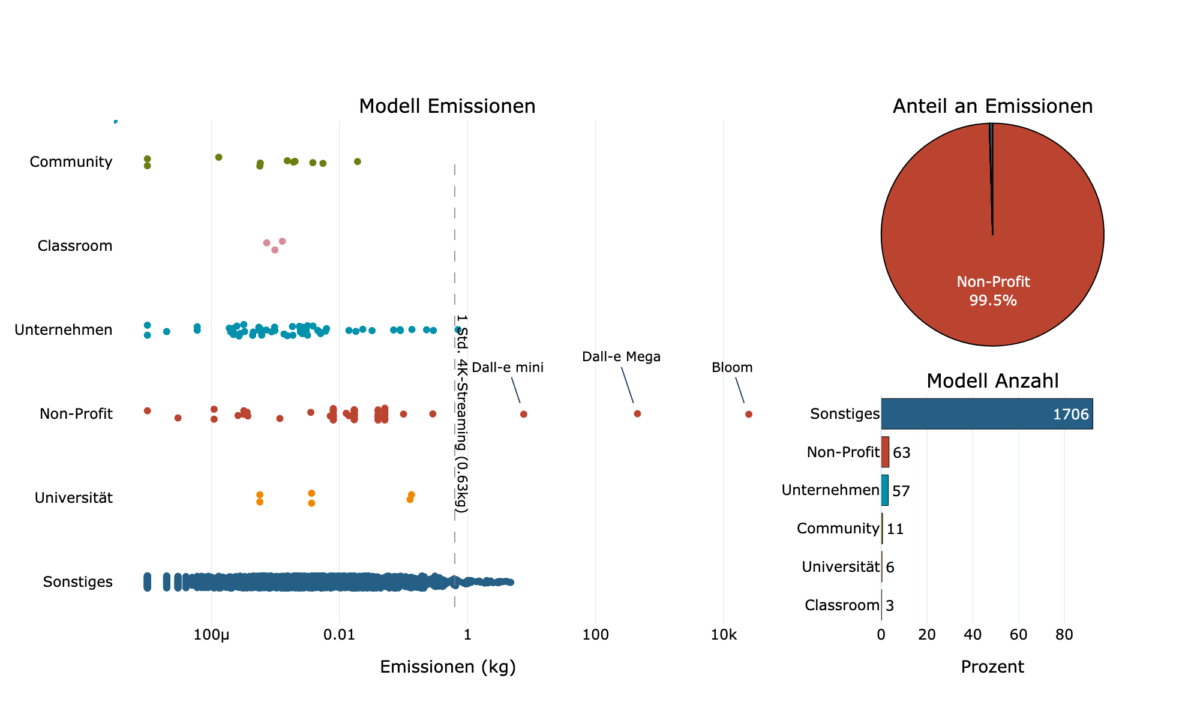
Große Modelle, große Emissionen. Kleine Modelle, kleine Emissionen
Die gute Nachricht zuerst: Das Training der meisten Modelle hat weniger CO2 ausgestoßen als das Streaming in 4K-Qualität für eine Stunde. Die schlechte Nachricht ist, dass nur etwas mehr als 1% der Modelle bei Hugging Face diese Informationen liefern. 1706 dieser 1846 Modelle, die Emissionsinformationen enthalten, stammen aus der Gruppe „Sonstiges“. Allerdings stammen 99,5 % der Emissionen von Non-Profit-Modellen. Das bedeutet, dass das Training nur einiger weniger Modelle den größten Anteil an den Emissionen ausmacht. Dies unterstreicht, dass der größte Teil der Emissionen von Großprojekten und nicht von kleineren Projekten stammt. Es macht aber auch deutlich, dass es mehr Transparenz braucht und die Emissionen konsequenter dokumentiert werden müssen.
Unterm Strich
Hugging Face ist die wichtigste Plattform für den Austausch vortrainierter ML-Modelle. Ohne eine Plattform wie diese hätten die meisten kleineren KI-Projekte keinen Zugang zu den neuesten Modellen. In gewisser Weise spiegelt Hugging Face den aktuellen Trend in der ML-Forschung wider: Das Feld wird von einigen wenigen Akteur*innen dominiert, die über die Ressourcen verfügen, immer größere Modelle zu trainieren. Obwohl das Training großer Modelle auf Akteur*innen mit ausreichenden Ressourcen beschränkt ist, ermöglicht Hugging Face Projekten mit weniger Ressourcen, diese Modelle zu nutzen. Auch zeigt es sich, dass zwar große Unternehmen die meiste Aufmerksamkeit auf sich ziehen, es aber eine lebendige Basis von kleinen und mittelgroßen Projekten gibt, die einen konstanten Output und nur geringe Emissionen haben.
Methode & Einschränkungen
Alle Daten wurden Anfang Juli 2023 gewonnen. Da der Fortschritt in der ML-Forschung schnell voranschreitet, sind die Zahlen möglicherweise nicht mehr aktuell. Für Informationen über die Modelle wurde die Hugging Face-API verwendet. Benutzer*innen haben die Möglichkeit, Informationsblätter, sogenannte Karten, hochzuladen. Diese Karten enthalten Informationen über Organisationen, Datensätze oder Modelle und sind die Hauptinformationsquelle für diesen Artikel. Die Informationen über die Organisationen wurden mit einem eigenen Scraper abgerufen. Alle Informationen über Organisationen sind Selbstangaben und es gibt viele leere Repositorien und Fake-Organisationen. So bietet Hugging Face laut seiner eigenen Suchfunktion zwar mehr als 260.000 Modelle an, aber nur etwa 150.000 dieser Repositorien sind größer als zehn Megabyte. Da ML-Modelle viel Speicherplatz benötigen, ist es unwahrscheinlich, dass diese Repositorien tatsächlich Modelle enthalten. Der allgemeine Trend sollte korrekt sein, aber einige Details könnten ungenau sein. Die detaillierten Informationen zu den einzelnen Organisationen wurden manuell und nach bestem Wissen abgerufen.
Alle Daten sind unter https://github.com/SamiNenno/Inside-Huggingface einsehbar.
Dieser Beitrag spiegelt die Meinung der Autor*innen und weder notwendigerweise noch ausschließlich die Meinung des Institutes wider. Für mehr Informationen zu den Inhalten dieser Beiträge und den assoziierten Forschungsprojekten kontaktieren Sie bitte info@hiig.de

Sami Nenno

Jetzt anmelden und die neuesten Blogartikel einmal im Monat per Newsletter erhalten.

Künstliche Intelligenz und Gesellschaft

Kann KI die Demokratie stärken? Ein Datensatz zu KI-Projekten, die demokratische Prozesse unterstützen möchten
Ein Datensatz mit über 98 KI-Projekte mit demokratischem Anspruch dient als Grundlage für mehr Forschung zu KI und Demokratie.

Zwischen Zensurvorwurf und Plattformmacht: Was der Digital Services Act wirklich regelt
Der DSA wird zunehmend als "Zensurgesetz" angegriffen. Dieser Beitrag argumentiert: Im Kern soll das Gesetz die Meinungsfreiheit im digitalen Raum schützen.

Demokratie zum Ankreuzen: Unsere Wahlkabine bei der Langen Nacht der Wissenschaften
Wir haben Berliner*innen eingeladen, ihre Haltungen zu Demokratie in Deutschland zu teilen. Die Ergebnisse erscheinen hier in Kürze.