Making sense of our connected world

From Alma Mater to Algo Mater – How Big Data Changes the Educational Landscape
The Educational Sector benefits from efficiency- and therefore has a pressure to digitise. On one hand, digital, interactive, and customizable teaching and learning materials can be used by teachers and students to improve their learning experience, making it faster and more successful. On the other hand, these digital learning and collaborative deals observe, analyse, and evaluate every step of the user. This not only has consequences on the user, but also impacts the ever-increasing amount of data in the thorough analysis of the education sector. The Alexander von Humboldt Institut for Internet and Society and the Vodafone Institute for Society and Communication invited to a keynote discussion about changes in the education sector through software opportunites and Big Data.
Das Lernen verändert sich. Lehrende können immer mehr von modernen Software-Angeboten profitieren. Statt zu Lehrbüchern greifen viele zu digitalem Lehrstoff mit integrierten Tests und Prüfungen. Dabei wird der Umgang des Lernenden mit dem Lehrstoff genau dokumentiert. Wie lange, wann, wo und in welcher Intensität wurde mit dem Lehrstoff umgegangen? Wie lange hat der Lernende gebraucht, um welche Frage zu beantworten? Wo war er/sie besser als der Durchschnitt, wo schlechter? Welche Inhalte hat er/sie schon im Langzeitgedächtnis gespeichert, welche müssen noch wie oft wiederholt werden?
Mit der Digitalisierung der Lernstoffe sowie der Erhebung und Analyse der Nutzungsdaten ändert sich nicht nur das individuelle und kollaborative Lernen, sondern es gerät der gesamte Bildungssektor in Bewegung: Anbieter von Lerninhalten entwickeln sich zu Softwareanbietern und Datenanalysten, Lernende, Lehrende und Schulen werden unter anderem zu intensiven Software-NutzerInnen. Innovationen im Schul-und Weiterbildungsbereich hängen bei einer erfolgreichen Digitalisierung des Sektors sehr stark von eben diesen Software-Anbietern ab, die wiederum sehr stark auf die Daten zurückgreifen, die Lehrende und Lernende im Umgang mit ihrer Software produzieren.
Das führt im Wesentlichen zu zwei Fragen, die anlässlich des Keynote Dialogs am 22. Juni unter dem Titel “From Alma Mater to Algo Mater” in der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) in Berlin diskutiert wurden. Wie sollten digitale Lernprodukte beschaffen sein und welche Möglichkeiten eröffnen sie nicht zuletzt durch die intensive Analyse von Daten den Lernenden? Und zweitens: Wie kann man den Umgang mit den persönlichen Daten der Lernenden so regeln, dass deren persönlichen Freiheitsrechte uneingeschränkt bleiben und sie keine Nachteile durch die intensive Analyse ihrer Lerndaten erleiden.

Die Protagonisten des Abends (v.l.n.r): Richard Heinen, Jessica White und Yoni Har Carmel
Jessica White, Beraterin beim Bildungsanbieter McGraw Hill Education, übernahm den Part der digitalen Protagonistin und erklärte die Vorteile der Digitalisierung im Bildungssektor. Yoni Har Carmel, Forscher am Haifa Center of Law and Technology spielte zwar nicht den digitalen Antagonisten, aber er machte aufmerksam auf die Risiken, die vor allem im Bereich Datenschutz mit der Digitalisierung des Bildungsbereichs einhergehen und skizzierte die Prinzipien einer Regulierung, die den Schutz der Nutzerdaten, d.h. der persönlichen Daten der Lernenden sicherstellt, ohne digitale Innovationen zu blockieren. Richard Heinen, wissenschaftlicher Mitarbeiter am Learning Lab der Universität Duisburg-Essen moderierte den anschließenden Dialog zwischen den SprecherInnen und den Gästen dieses Abends.
Die Vorteile digitalen Lernens
Jessica White hob vor allem die Vorteile digitalen Lernens hervor. Interaktive und personalisierte digitale Lernstoffe eröffnen Lernenden einen sehr viel individuelleren Umgang mit den zu erfassenden Inhalten. Sie können ihn in ihrer eigenen Geschwindigkeit erarbeiten, integrierte Tests- und Prüfungsfragen messen den Lernerfolg und passen auf Basis der erzielten Lernerfolge Menge und Schwierigkeitsgrad des noch zu erarbeitenden Stoffes an. “Da in kollaborativen Lernformen die Lehrenden über die individuellen Lernfortschritte informiert sind, können sie sehr viel intensiver auf die Lerndefizite der Lernenden eingehen und sie überwinden helfen”, erklärte White. Das führe zu einem insgesamt sehr viel effizienteren Lernprozess, der Lernenden wie Lehrenden zugute komme. Allerdings, so White, weiter bleibe das Verhältnis zwischen Lernenden und Lehrenden auch im digitalen Zeitalter ein zentrales Moment des Lernerfolges.
Laut White bringt die Daten-basierte Art zu lernen einige Vorteile:
- Personalisierte Lernerfahrung
- Mehr Engagement der Lernenden
- Daten getriebene Entscheidungen
- Bessere Lernergebnisse
White und ihr Arbeitgeber McGraw Hill definieren die für diese Art des Lernens zu erhebenden Daten und ihre Analyse als “Small Data”. Small Data sind die Daten, die aus dem Umgang von Lernenden mit ihrem Lernstoff erwachsen – zum Beispiel Daten über den Umgang des Lernenden mit dem Lernstoff: Wie lang beschäftigt er/sie sich damit, wie überzeugt ist er/er, den jeweiligen Lernstoff zu beherrschen, wie lange benötigt er/sie, um bestimmte Aufgaben zu bewältigen und wie viel Prozent des Stoffes hat er/sie wie auswendig gelernt? Einen Big-Data-Ansatz, der beispielsweise das Verhalten der Lernenden außerhalb einer konkreten Lernsituation berücksichtigt oder seinen familiären Hintergrund einbezieht, pflegt McGraw Hill nicht, betont White. Sie sieht das Vorgehen von McGraw Hill durch die Lernendenselbst bestätigt. 75% der Lernenden, die in den Genuss dieser Form des digitalen adaptiven Lernens kommen, halten sie für “extrem” oder “sehr” hilfreich.
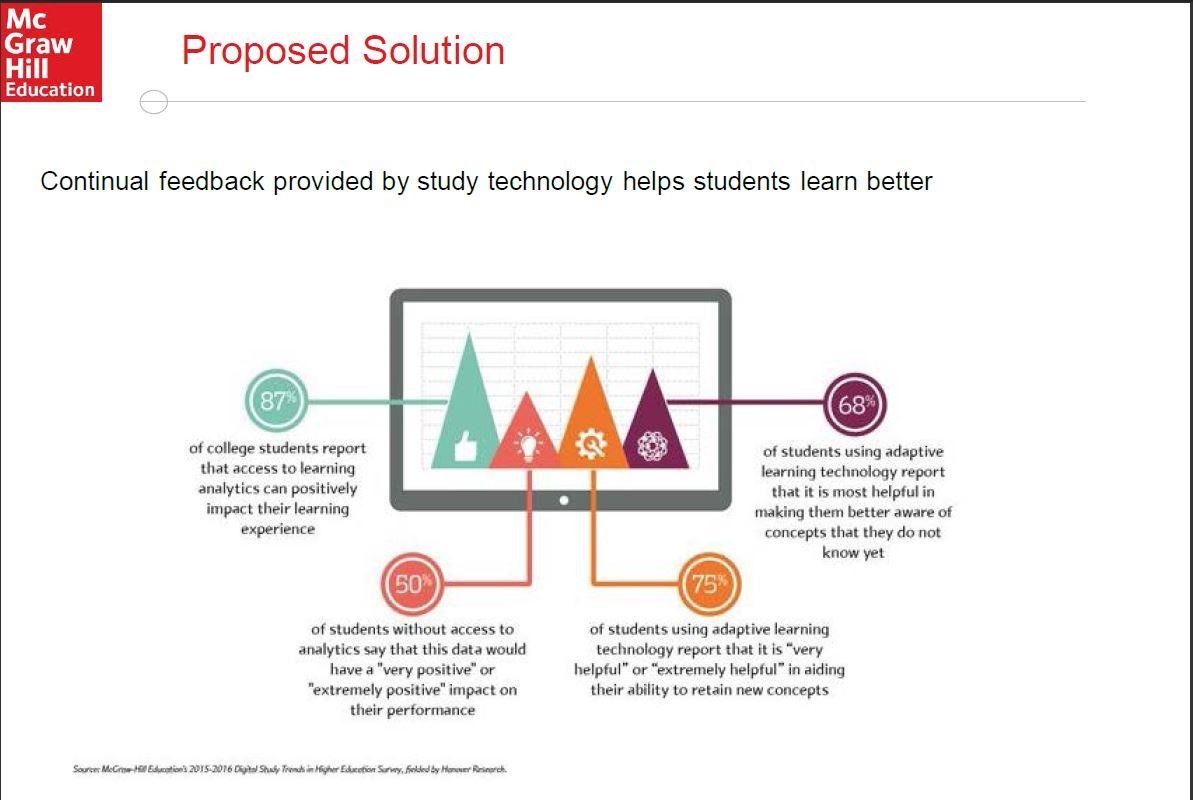
Die deutliche Mehrheit der Lernenden erachtet digitale Lernstoffe als hilfreich.
White ist sich allerdings bewusst, wie sensibel der Umgang mit Daten von Lernenden ist. “Wir geben die Daten nicht an Dritte weiter. Die Daten gehören den Lernenden, den Universitäten und den Bildungseinrichtungen. Wir nutzen sie ausschließlich, um die Lernerfolge der Lernenden zu verbessern.”
Daten beeinflussen die Zukunft der Lernenden
Yoni Har Carmel bezweifelt die Vorteile der digitalen Lernformen in keiner Weise. Allerdings weist er darauf hin, wie viele Daten – also Identitätsdaten, demografische Daten, psychologische Profile, Noten, Anwesenheitsdaten, disziplinäre Daten, Finanzinformationen, Interaktionsdaten – über Lernende gesammelt werden und wie groß der Einfluss dieser Daten auf die Zukunft der Lernenden ist.
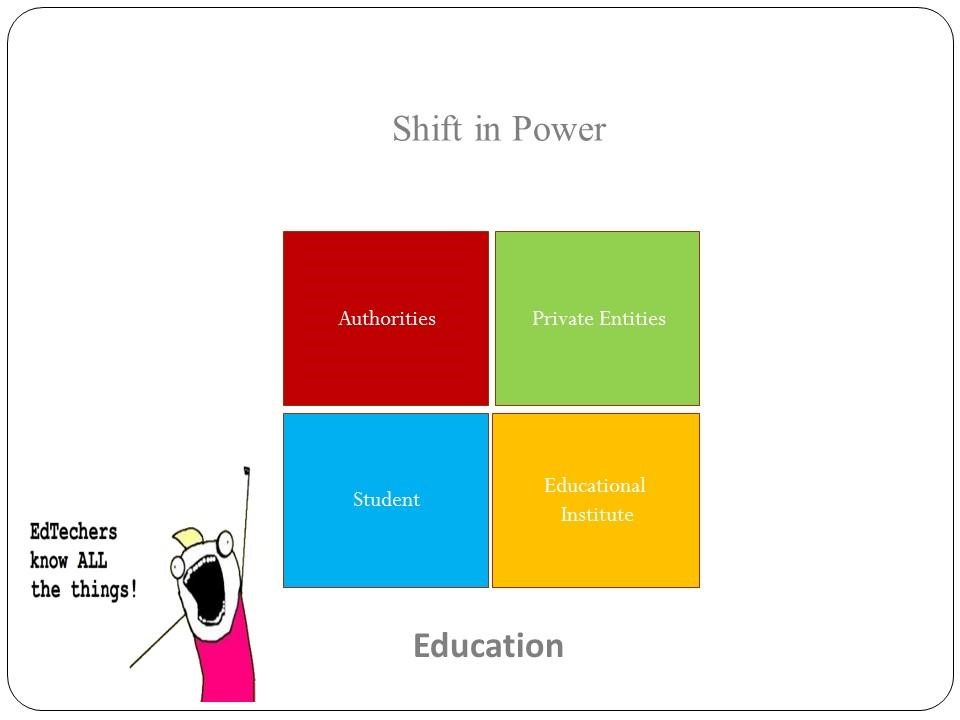
Nicht mehr die Bildungseinrichten verfügen über die Daten, sondern die Anbieter der Lernprodukte (Quelle: Yoni Har Carmel)
Dabei geht es Carmel nicht nur um die Daten, die im Umgang mit Lernstoffen erhoben, gespeichert und analysiert werden. “Viele Schulen und Universitäten sind nicht in der Lage, diese Daten selbst zu speichern, zu verarbeiten und zu analysieren. Sie werden von privaten Unternehmen wie Google, McGraw Hill, Pearson, Microsoft, Apple usw, verarbeitet. Sie können diese Daten analysieren, ja sie können Ausbildungsentscheidungen auf Basis dieser Daten treffen. Die Daten werden über Algorithmen analysiert, nicht von Menschen interpretiert.” Damit kommt es wahrscheinlich zu einer “Machtverschiebung weg von den Bildungseinrichtungen hin zu diesen profitorientierten Anbietern.” Da Wissenserwerb sich in Zukunft immer stärker Richtung Web und digitaler Inhalte entwickeln dürfte, müsse man davon ausgehen, dass die Rolle dieser Anbieter im Bildungssektor bedeutsamer werde.
Carmel sieht vor allem drei Gefahren, die durch Regulierung eingedämmt werden:
- Eingeschränkte “intellectual privacy” – dieser von Neil Reichards eingeführte Begriff beschreibt das Recht des Einzelnen, Ideen und Meinungen zu entwickeln, ohne sie ungewollt fremder Beobachtung oder Einmischung auszusetzen.
- Eingeschränkte Bildungsgerechtigkeit und Chancengleichheit – Um die Gefahren zu belegen, zitiert Carmel aus einem Bericht des Weißen Hauses aus dem Jahr 2014. In dem Bericht mit dem Titel: “Big Data: Seizing Opportunities, Preserving Values” heißt es: “Die verstärkte Benutzung von Algorithmen um Auswahlentscheidungen zu treffen, sollten genau auf potenziell diskriminierende Ergebnisse für benachteiligte Gruppen überwacht werden, selbst wenn dabei keine diskriminierende Absicht vorliegt.” Auf den ersten Blick erscheinen Daten getriebene Entscheidungen neutral, wissenschaftlich und gerecht. Allerdings, so Carmel, basieren auch Algorithmen auf bestimmten Annahmen, die gewisse Einstellungen zu Bildungsgerechtigkeit widerspiegeln, welche die Daten basierende Analysen beeinflussen können.
- Frühzeitige und unkorrigierte Einstufung der Lernenden als unzureichend – Scheitern und Erfolg werden langfristig dokumentiert. Lernende, die anfangs nicht erfolgreich sind, stehen viel stärker unter Druck. Algorithmen interpretieren, welcher Erfolg und welcher Misserfolg wie schwer wiegt. Hier besteht die Gefahr, dass Misserfolge zu hoch bewertet werden.
Regulierung mit Augenmaß
Carmel fordert deshalb eine Regulierung des Bildungsbereichs – aber eine mit Augenmaß. Vielleicht werde Big Data den Bildungsbereich umkrempeln, vielleicht sei eine Machtverschiebung in diesem Bereich weg von den Schulen und Universitäten hin zu den Anbietern von Lerninhalten unvermeidlich. Aber es wäre unvernünftig, vorwärts zu stürmen, ohne den Schutz der Daten der Lernenden sicherzustellen.
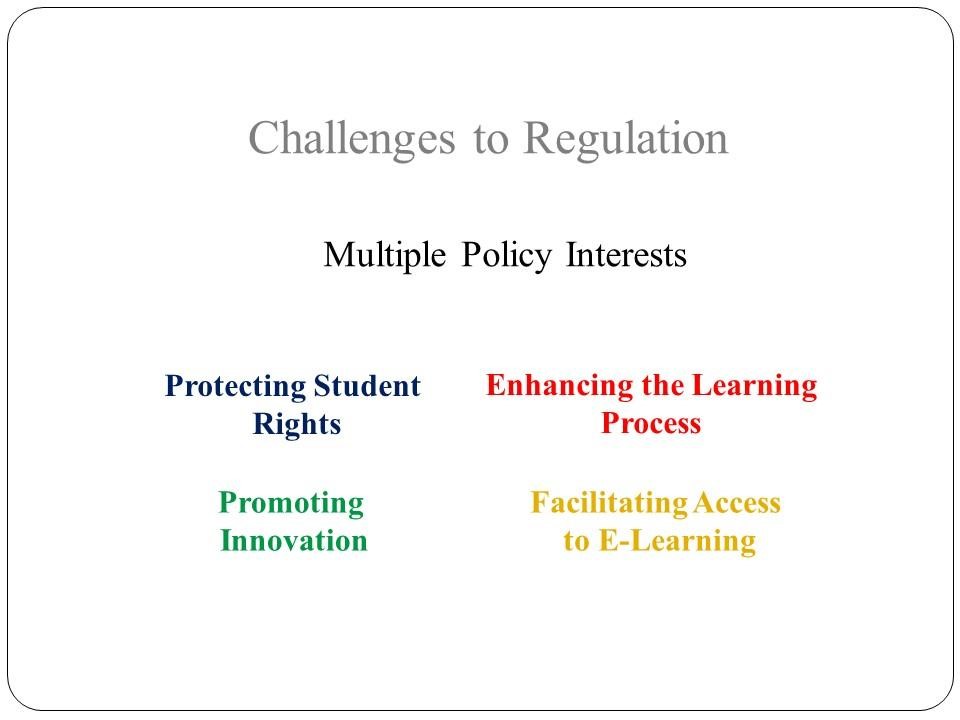
Eine mögliche Regulierung muss die Balance halten zwischen den Datenschutz-Rechten der Lernenden und Innovation. (Quelle: Yoni Har Carmel)
Zunächst müsse sehr genau definiert werden, welche Risiken überhaupt bestehen, dann sollten sehr sorgfältig Regeln definiert werden, welche” die Rechte der Lernenden an ihren Daten schützen, aber Innovation nicht blockieren. Carmel schloss mit einem augenzwinkernden Hinweis an die Anbieter von Lern-Software und Analyse: “Ich bin sicher, dass Unternehmen, die Lerninhalte individualisieren, auch Datenschutzbestimmungen individuell anwenden können.”
This post represents the view of the author and does not necessarily represent the view of the institute itself. For more information about the topics of these articles and associated research projects, please contact info@hiig.de.

You will receive our latest blog articles once a month in a newsletter.

Digital future of the workplace

Prompt to perform? Sustainable talent management in the age of generative AI
What impact will generative AI have on talent pipelines? How must companies rethink their talent management?

AI between climate change and climate protection
How do climate change and artificial intelligence interact? How AI can help in the fight against climate change?

Digital by design, not by default: Resilience in higher education
What does resilience in higher education look like? A comparison of two models from Germany and Portugal shows: there is no single formula.